IV. The Process of Discovery
Research can be “top down” or “bottom up.” You can have a general view of how things work and want to expand or test that paradigm. Alternatively, you may see a behavior and wonder why it works the way it does. Research can be classified in terms of these strategic approaches. There are two major classes of systematic research. Each class generates knowledge by using a different logical approach.
This class of systematic research begins from some knowledge base, attempts to extend that knowledge base by making a prediction, and then verifies that extension by comparing the prediction to empirical results. Discovery is made by specifically designing research to provide some result which is consistent or inconsistent with the predictions of the theory. In this regard the actual experimental procedure and results have no intrinsic interest other than confirming or falsifying the set of principles which were used to make that prediction. Nobody cares that the pigeon pecks a blue key more slowly on a VI 240-sec than when on a VI 60-sec schedule. Whether it is a pigeon or a human being, whether it is a blue light or a yellow light, and whether it is a VI or an FR are all seen as irrelevant. What researchers care about is that behavior is a function of reinforcement rate, and that decreased reinforcement rate decreases the probability of the behavior which it supports. In general, if you think a theoretical explanatory system has a flaw because you think a behavior is the result of some other process, you are doing deductive research.
a. Discovery Via Premeditated Design
i. Comparison of Results to an A Priori Prediction
In this type of research the study is specifically designed with the intent to compare some aspect of the results to what was predicted to happen. If the pigeon pecks the left key, one theory is supported; if it pecks the right key, then some other theory is supported.
That deductive prediction can be based on your intuition, e.g., “I don't know why, but I’ll bet the subjects will do xxx if the environment changes to yyy.” We often have knowledge we can’t clearly articulate. When our intuition is at variance with accepted knowledge, however, we must do research to either better the field or better ourselves.
That deductive prediction can be based on a theory which predicts a relationship, e.g., “if deprivation is increased then the rate will increase.” This is the prototypical “scientific method” presented in textbooks. It is important that you clearly understand the theory and clearly think through every possible result before doing this type of research. Virtually all the work is in the design. Design the research so that you will have something positive to say no matter what happens. It is a powerful methodology because if done right the results always bear on the paradigm. Normally you will be able to publish the results no matter what happens. “Negative” results simply mean that the researcher didn’t plan ahead. This approach is an ideal methodology for dissertations because it won't leave you “snookered.”
(c) Based on Model (quantitative theory)
That deductive prediction can be based on a model which specifies an exact quantitative value, e.g., "if reinforcement rate on x is decreased by one-half then response rate on y should increase by one-third. This type of quantitative theorizing and testing is of growing importance and is the future of psychology.
ii. Post Hoc Realization of Functional Relationship
Very often data are generated in an experiment (specifically designed to reveal a particular phenomenon) beyond those which support or refute a deductive prediction. Functional relationships other than those of our original interest may be observed in the data of a design premeditated to simply evaluate a prediction. We should make the most of the hard work we put into doing research by squeezing every possible piece of information out of it.
This second research philosophy begins from some observational or experimental result and attempts to integrate the finding within some theoretical context. Whereas deductive research starts with theory and implements a behavioral test, inductive research starts with a behavior of interest and searches for an integrated context.
The interest in the particular functional relationship may be the result of its support or refutation of some implicit paradigmatic expectation. Interesting or surprising results are usually those for which our explicit or implicit paradigm did not prepare us. As a result the separation between deductive and inductive research can sometimes be fuzzy. In general, if you observe some behavior and wonder why, then you are doing inductive research.
a. Discovery Via Post Hoc Organization of Data
i. Comparison of Results to Known Functions
This is reorganization, rearrangement, and restructuring of data in order to determine whether or not it matches a relationship which you predict. This type of “playing” with the data has particular regularities in mind. You analyze your data looking for specific functions. These functions could be generated by theories, models, or even intuition as in deductive research.
ii. Description of Functional Relationship
Very often things happen in an experiment for which you have no preexisting knowledge and no particular "ax to grind." Functional relationships other than those previously documented may be observed. In this case your primary task is one of accurately and completely describing a phenomenon whose larger context and set of controlling factors you can only guess, i.e., the construction of a functional context.
We can have a hunch about the ultimate nature of the functional relationship and analyze and display our results to best point toward it.
(b) Eventuating in a Theory
We may be able to formalize our intuition into a general theoretical model which makes clear predictions and is falsifiable.
(c) Eventuating in a Model (quantitative theory)
We may be able to formulate an exact model of the obtained functional relationship and wish to argue that that model is applicable in other situations.
b. Discovery Via Construction of Functional Context
This general class of inductive research, not only reorganizes data to see what's there, but also carries out specific experimental procedures in order to better characterize the phenomenon which is of interest. It is similar to “description of functional relationship” but is broader in that it specifies how the function changes with changes in procedures.
x
Unless you have perfect knowledge, research is required in order to know whether or not a variable was effective. Without complete knowledge, you must gather information, interpret the results, and make a decision.
Given that you are taking a generally deductive or inductive approach, you then must design your research so that you are most likely to arrive at the truth. This requires that you exclude both confounds and chance as plausible explanations for your results. Otherwise, you really have nothing credible to offer the research community.
a. Difference Measures to Cancel Confounds
An experiment is a method of exposing and understanding the cause of an effect. It must be remembered, however, that any candidate is not necessarily the "true" cause, and you are in search of the "true" cause. It is very difficult to see only the relationship between some very specific input and some very specific behavioral output. The organism is receiving many other inputs, has a long history of interacting with the environment, and has many organismic factors affecting the output. In addition, the organism is always doing many many things. It never does only one isolated thing.
Luckily, an approach is available which isolates just the input and output factors in which you are interested. The approach is based on the realization that subtraction removes all factors that are the same and leaves only those factors that are different.
Suppose that you want to measure the effect of the caffeine in coffee without measuring the effect of drinking the coffee itself. Weighing a liquid with a pan balance is an apt metaphor for this experiment. Liquid alone cannot be put on one side of the balance. It will run off the edge of the pan. To measure the weight of a liquid, you must have the liquid in a container. The container is an unwanted but unavoidable aspect of weighing water. It is a confound in that you only want to know the weight of the water. In order to weigh just the water, an exactly equivalent container without the liquid must be placed on the other pan in order to remove the effect of the container on the weight of the liquid in the container on the other pan. Only the difference between the two pans (i.e., water only) affects the weight indicator (i.e., dependent variable). If you wish to measure the effect of caffeine without the coffee, then you give a person decaffeinated coffee on some days and caffeinated coffee on other days in that way, only the difference in the treatments (caffeine) will be isolated and its effects can be measured as the difference between the behavior on coffee plus caffeine days and coffee without caffeine days.

In the pan balance example, only the water can be causing the balance to shift from zero. The containers are exactly equivalent. An experiment can be seen as doing whatever is necessary to arrange exactly identical conditions on both sides of the balance except for the independent variable (the water). Any difference in the dependent variable (the pointer) is caused by the independent variable. Any difference between the two experimental conditions (the containers) is a confound and is an error.
The following simplified semialgebraic analogy may further illustrate the point. Suppose the nearly infinite number of possible stimuli (inputs) in a crowded cafeteria are represented as,
A + B + C + D + E . . . .
(these are the contents of one pan in the above figure). And the equally nearly infinite variety of behavior (outputs) in that cafeteria is represented as,
V + W + X + Y + Z . . . .
(which represents the deviation of the pointer from the center of the scale). The fact that the general behavior which is occurring can be roughly attributed in some way to the situation can be depicted, therefore, by,
A + B + C + D + E . . . . ----------> V + W + X + Y + Z . . . .
(the weight in the pan causes the needle deviation). Now suppose that you are in the cafeteria and see a very attractive potential date sitting a few tables away. You add a smile and a nod to the mass of stimuli in the cafeteria.
A + B + C + D + E . . . . + P ----------> V + W + X + Y + Z . . . .
Much to your satisfaction, the total behavioral picture in the room changes to include a smile, nod and a wave in return.
A + B + C + D + E . . . . + P ----------> V + W + X + Y + Z . . . . + S
A, B, C, D, E, and P can be seen as the causes for V, W, X, Y, Z, and S. However, we are actually interested in only a subset of all possible causes (i.e., P). We don't really care about the smell of hamburgers. Additionally, we don't really care about all possible dependent variables (e.g., people moving around and talking). We really only care about the wave (i.e., S).
You can apply a bit of reasoning and find that you can cancel all the stimulus factors that were the same before and during your additional stimulus as being extremely unlikely candidates for causing the change in the mass of behavior in the cafeteria. (Things that are the same on both sides of a pan balance cannot be the cause of a deviation in the pointer.) Your additional stimulus and the subsequent reply are the only events remaining after all the "causes" and "results" that were the same canceled. It is as if you could algebraically subtract the before from the after.
A + B + C + D + E . . . . + P ----------> V + W + X + Y + Z . . . . + S
A + B + C + D + E . . . . ----------> V + W + X + Y + Z . . . .
-------------------------------------------------------------------------------------------------------------
/
/ /
/
/
+ P ---------->
/
/
/
/
/
+ S
You could accept, therefore, that your wave caused the reply. Any difference in results must be because of differences in the causes. (Any difference in the weights must be because of differences in the "pans.")
Your reasoning was good as far as it went. Unfortunately you may find that you made an error in assuming too much. If all conditions were not the same (as they rarely are in a crowded cafeteria), all factors do not cancel out.
(after) A + B + C + D + E . . . . + PQR ----------> V + W + X + Y + Z . . . . + S
(before) A + B + C + D + E . . . . ----------> V + W + X + Y + Z . . . .
------------------------------------------------------------------------------------------------------------------------
/
/
/
/
/
+ PQR ----------> /
/
/
/
/
+S
For example, someone else behind you could have been smiling and waving also. You would then be left uncertain as to exactly what caused the effect. The wave could be for you or it might be for the other person. Note that because of the confound you don't know whether the wave was for you or for the other person. It is not the case that you know that it was not for you.
Your independent variable (P) can be thought to cause the change in the dependent variable (S) only if all factors cancel and are proven irrelevant. Anything that changed and was not corrected for (i.e., Q + R) may be the actual cause and does lead to the possibility of alternative explanations for an obtained result.
Variables that you are not explicitly testing must be kept constant. Remember that the idea of an experiment is to reduce or eliminate alternative explanations for what you are demonstrating. If you allow potentially relevant variables to fluctuate in an uncontrolled fashion you cannot be sure what caused the effect. Was it the result of the change which you deliberately caused or was the effect the result of the other confounded changes? You are left with very little that you can say with confidence. A solution for the cafeteria example would be to stand with no one else behind you or add an additional test such as moving to a new spot and waving again.
Typically experiments contain two exactly identical groups treated exactly the same except for the independent variable ( your wave is the ONLY thing that is different). For example, two groups, one given a pill with a drug (experimental group) and the other with an identical pill without the drug (control group). This can be represented as
(experimental) A + B + C + D + pill . . . . + drug ----------> V + W + X + Y + Z . . . . + S
(control) A + B + C + D + pill . . . . ---------> V + W + X + Y + Z . . . .
----------------------------------------------------------------------------------------------------------------------------------
/
/
/
/
/
+ drug ---------->
/
/
/
/
/
+ S
"drug" represents the independent variable; S represents the dependent variable. A + B + C + D + pill ---- represents contextual, constant variables. Any variable that you want to eliminate as a potential cause should be eliminated by making it the same in the control group. It will therefore be canceled out.
To accurately assess a functional relationship, you must make absolutely certain that the confounding influences have been removed or at least held constant so that they do not have a changing effect on different parts of the experiment. Your major adversary in the quest for truth is the uncontrolled variable. If uncontrolled variables could have been present you will not know for sure what, if any, effect the independent variables had had.
Part of the very great brilliance of Pavlov's discovery (that pairing a bell with meat powder resulted in salivation to the bell) was the realization that he must separate naturally occurring intrinsically grouped things in order to determine causation. If we are to discover the cause for salivation to the sight of meat, then we must separately manipulate "sight" so we can have meat with the sight of it and meat without the sight of it.
In group designs, different groups of subjects serve in the treatment and control conditions. Clearly, the two groups must be as similar as possible and must be treated as much the same as possible, with the exception of the independent variable. In this way, everything but the independent variable cancels out as a potential cause for the difference in the dependent measures.
ii. Single Subject Design
Single subject designs are
used because they provide the most powerful technology to detect treatment
effects and provide the greatest generality to other situations. If every
single animal exhibits the same functional relationships, then it is very
likely that a target animal will also exhibit the same relationship. In
single subject designs, the same individual serves as both the treatment "group" and the control "group." How the individual behaves under the treatment is compared to how that same individual behaved both before and after the treatment.
The “before” and “after” conditions and their resulting behaviors are used to cancel out the effects of the unwanted confounds as potential causes of the resulting behaviors during the treatment condition. Only the difference in the conditions are the likely causes for the difference in the behavior.
b. Assumption That Unlikely by Chance is True Effect
Given that you have removed confounds as a cause for your obtained results, you now must determine if the results were simply the result of chance or were the result of a true treatment effect.
You are in a situation much like a judge; you must decide whether or not a treatment was effective, or whether or not the findings were meaningful.
The following figure illustrates the details of the task that faces us. Imagine a party where the noise levels are sometimes very loud and sometimes very quiet. Add the task of having to decide if someone knocked at the door. Suppose they just tapped the door? You would not hear it. Suppose they hit the door with a sledge hammer? Surely you would hear it. What about all the variations in between? If they continually knocked harder and harder, at what point would you just hear it? Any possible ratio of signal to noise can occur.
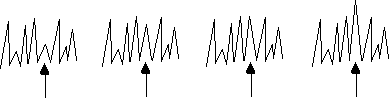
The continuous function below is the result of all possible signal-to-noise ratios illustrated in the above figure. Unfortunately, the information upon which decisions are based is not a simple step function like the dashed line in the following figure, rather it changes gradually and continuously like the solid line. Except in the most trivial of cases decisions must be based on information which can take on any value. We cannot wait for a sledge hammer. The infinite series of ratios, each one slightly larger than the one before, is well illustrated by the increasing light levels with sunrise. The task is to decide when is it daylight.
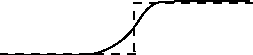
Further, the results of decisions are not always equal and irrelevant. You cannot simply do whatever you feel like doing at the time. Decisions must in fact be based on a weighing of the pros and cons of each outcome and comparing the net result to your “criterion” or the point you choose for when enough is enough. Both science and law reject capricious decisions.
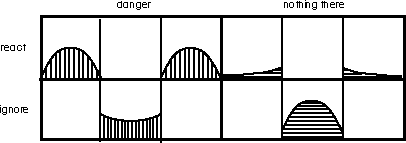
A detailed, analytical example will help. Suppose you are camping out in very remote terrain and you hear a noise. What should you do? Go back to sleep? Run for a tree? Or, turn off the television and turn down the electric blanket? One of two actual events could have happened. A dangerous one or an insignificant one. You could behave in one of two ways: you could have reacted to the event, or you could have ignored it. The figure below illustrates the four possible occurrences.
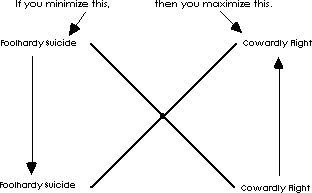
If you ignored it when nothing was there (peaceful sleep) you got a good night's sleep and were safe. If you ignored it when there was danger you died (foolhardy death). If you reacted when there was nothing there (cowardly flight) you spent the night shivering in a tree for no reason. If you reacted when there was danger (lifesaving escape) you saved your life. Note that whatever you do (react or ignore) is the result of a decision.
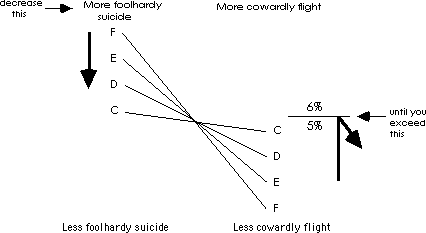
The two types of errors are inversely related; they work like a “seesaw.” If you mindlessly minimize foolhardy death, you maximize cowardly flight. If you mindlessly minimize cowardly flight, you maximize foolhardy death.
You can be very safe by running at the slightest sound. Unfortunately the price is that you will never get any sleep. Choosing to run more often means losing more sleep.
Alternatively, you can be very macho and never run when you simply hear a noise. The price is being eaten by a bear sooner rather than later. If you must avoid being eaten (foolhardy death) at any cost, then that cost is an unavoidable increase in losing sleep for no reason (cowardly flights). If you must avoid being a coward (cowardly flight) at any cost then the cost is an unavoidable increase in being eaten (foolhardy death).
As can be seen decisions are actually a trade-off. Given that you want to avoid being eaten (correct detection) how many sleepless nights are you willing to spend? 100%, then spend all night every night up a tree with search lights on and a gun? 0%, then don't worry about a thing --- when your time comes you will be gone. 1%, When you hear roaring and trees breaking run for your life. The point is that you must choose a balance between gain and loss. How many sleepless nights against how much safety. More correct detection cost more false alarms. More correct rejections cost more misses. Decisions actually concern the proportion of each type of error you are willing to tolerate, not whether or not something “really” happened. Your philosophical trade-off point is called your criterion. Given the criterion the decision is simple and is based on the facts. You become a creature of rule rather than guess.
You would essentially say “be as safe as possible as often as possible up to about five nights per 100 up a tree for no reason.” The following figure illustrates this: reduce foolhardy suicide as much as possible until it starts costing more than five nights out of a hundred up a tree for no reason.
The actual distribution of events like wind noises in the woods is normally distributed. Events very different than the mean are unlikely to occur by chance. Very loud or very soft noises are not likely to happen in the woods by chance. The chance curve is depicted as the gaussian distribution in the figure. It is filled with horizontal lines. For pedagogical purposes we can depict the probability of events which are dangerous with an area filled with vertical hatch marks. Note that this function is actually the left tail of a distribution of bear (loud) noises above (to the right of the wind noises), as well as the right tail of a distribution of tiger noises below (to the left of the wind noises). This curve is arbitrarily set to be at its lowest at approximately the mean of the distribution of noises caused by chance but its minimum depends on where the upper and lower distributions meet. A very loud sound (Point F on axis) or complete silence (Point A) are both very unlikely to be the result of the wind or simply background noise and are very likely to be a non chance event (bear or tiger). For pedagogical simplicity, sounds (more precisely the production of quiet) from the tiger distribution will be ignored in future discussions (they are, in fact, identical in all regards to bear noises with the exception of being to the left rather than to the right). It can be seen that as we shift our criterion of when to run for our lives from C to D, E, and F we will be making fewer and fewer false alarms. We will be a coward less often. (The area under the chance curve beyond the criterion.) The horizontal cross-hatched area beyond our criterion will be smaller and smaller but, we will make more and more misses (the area under the effect curve within the criterion, i.e., the vertical cross-hatched area to the inside of our criterion will be larger and larger).
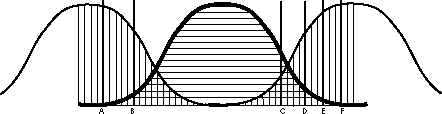
If we set our criterion for running for our lives to Points D and B we can illustrate the four possible outcomes of the decision matrix keeping in mind that the line above the horizontal lines depicts the chance curve and the line above the vertical hatch lines illustrates the effect curve.
You can examine two other everyday decisions with this same type of analysis. An accused person could, in fact, be guilty or innocent and you as a juror could vote to convict or exonerate.
A second example is given by dating. The other person could be willing or unwilling to go out with you on a date and you could ask or refrain from asking that person out for a date.
The abstract version of the decision matrix is presented in the following figure.
The logic underlying your decision is: 1) if the magnitude of the signal is really quite large compared to what happens by chance, then you are willing to accept that it was not chance (even though it could be chance), 2) it if was not chance that caused the signal, then if you do the treatment again, you will get the effect again (it is a reliable effect), and finally, 3) if the treatment reliably causes the effect, then the treatment "really works."
In sum, given that a result is not caused by a confound, a treatment effect is accepted as real if it is unusually large. If an effect is larger than our criterion, we declare that we are willing to accept that the treatment worked. Our criterion is a rationally determined point based on what happens by chance, and our relative valuation of false alarms and misses. Just as in dice throwing, when we bet on a 7 rather than a 2, we don’t know which will win (is true) in each situation, but we do know what to bet on in order to be right more often than not (make money).
a. First: Differences are Caused by Differences
First compare two treatment conditions which are exactly equal with the exception of the independent variable. Any difference in the result of those different treatments must be due to chance or true effect. "The difference in what was obtained was caused by the difference in what was done."
b. Second: Compare to Criterion for When Enough is Enough
Determine what happens by chance. Set your criterion to reduce misses as much as you can, consistent with not "paying" too many false alarms. If your obtained results exceed your criterion, then declare a true effect.
As previously stated, the outcome of any experiment can be the result of three causes: confound, chance, and true effect. Each investigator is obligated to consider each and make a case for which of the three was the most likely cause of the outcome. After rejecting confound as a cause, it is always possible that the result was only chance. Researchers deal with this by establishing a criterion past which they are willing to claim a true effect. Ultimately, it doesn’t matter if the effect was really a true effect because we will never have divine knowledge. Most often, researchers are unwilling to claim a true effect if the result was likely by chance. If you try to mentally cause a head to come up when you honestly flip an honest coin, and it comes up heads it is not a wise idea to declare that you have telekinesis. If you honestly flip an honest coin a thousand times and it comes up heads every time, you are in a different situation.
Experiments which produce results very unlikely by chance can either indicate the action of a confound or the action of a true effect. We normally know that the result is not due to a confound because we generated a control “treatment” which was exactly the same as the treatment except for the independent variable. The confound was removed by cancellation. We are, therefore, left with only a true treatment effect as the probable cause.
The following are some attitudes or tactics which are likely to bring you success in your research endeavor.
Nature does not give up its secrets easily. Choose a topic for which you will be willing to spend a great deal of time thinking about and working on. Have confidence in your own judgment (but, note #5 below). Be enthusiastic. Work in a social situation which keeps you working and thinking. Create the social situation which will provide the reinforcers you need if necessary. Simply put: Time is knowledge.
a. Reliable Robust Relationship
Independent variables which produce large effects or consistent effects are easier to measure and easier to separate from random noise and confounds.
b. Apt and Optimal Elements
Choose an optimal subject, apparatus, and procedure to research potential relationships. It is easier to use pigeons than whales as subjects. It is easier to detect a forward head movement which happens to be in front of a key, than to detect the dipping of a wing in free space or the behavior of thinking some thought. It is easier to control the presentation of food to a hungry organism than to control “life’s little pleasures.”
c. Large Potential for Gain
Some pieces of knowledge are simply more useful than others. Articulating a functional relationship which dramatically reduces the complexity of the existing paradigm, or which is a counter example in a previously coherent paradigm, provides a greater step forward than some simple "irrelevant" finding.
d. Drop Everything if Necessary
While seeing a problem through to completion is almost always the only acceptable research methodology, occasionally, a finding of such great significance occurs that we should drop everything and pursue the new problem.
Be careful not to fixate on a judgment error and try to prove it at all costs.
Some ways of characterizing complex relationships are better than others. Your task can be made very much easier with the right visualization. Analytical geometry was almost as great a step forward in our thinking as was language. The clear depiction of a relationship simplifies its understanding.
In general, it allows you to pass from depiction, to description, to the specification of the relationship with an equation.
a. Simplify to Essential Case
Discovery is much like mining. We must separate the inessential and confusing from the actual effect. We want to eliminate the uncontrolled variability which obscures the important effect. In sum, research elegance is the insightful use of simplicity.
b. Sort in Terms of Similarities and Differences
If you sort instances into positive and negative instances then you can define the boundary which separates them. That separation rule is a major advancement in our knowledge. Just the same as finding the outline of the steam shovel at the bottom of the lake made it obvious what it was.
c. Search for Regularities
Regularities provide you with a method of simplifying the booming confusion of nature. A single simple rule can extract or make comprehendible much of the obtained variance. For example, the fluctuating activity of an organism can be better understood by noting how it shifts with the light cycle.
d. Recognize Errors as Breakthroughs
If you make a wrong prediction either you discovered something about yourself or you discovered something about nature. In either cases you have gained because you or your model could be better next time.
e. Be Alert, Ingenious and Relentless
Knowledge will not be dumped squeaky clean into your lap. It will be like trying to find the motorcycle in the preface; you will have to actively make it make sense. If the knowledge has already been discovered, someone can tell you where to look and generally what you should see. But you are not trying to come to see what people already know. You are trying to discover something that no one has yet found. This is more difficult. If you are to be the first, then no one can show you where to look and what you should see. You will have to discover it for yourself. No one can guarantee that you are doing the right thing.
Some researchers have said that the task is like the mental equivalent of passing a truck in the rain. In order to advance, you must enter a period of intense confusion where the solution is not clear at all. In fact, nothing can guarantee that a solution is even possible. It makes you want to stop or turn back. But, if things go right, you pass through to clarity and you are much further ahead. Similarly dividing 3 digits into 6 digits in your head or discovering a conceptual solution to a new problem is very difficult, and requires intense and continuous attention. The difficulty makes you want to stop. But, once you have the answer, that answer is an easy thing to remember and use. This difficult, "scary," unclear, and bewildering challenge is sometimes referred to as "working your way through the fog of death."
Building on the discoveries of others is very much more productive than reinventing the wheel. In general reading time will pay off more than “doing” time. Use reading time to get wisdom and to spark ideas. Use “doing” time to clearly prove that you were right or wrong.
Strike a balance between following the existing paradigm with tried and true procedures and tried and true conceptualizations, and breaking new ground with new conceptual approaches. Old ground is safe but boring. New ground is exciting but risky. The problem is similar to building a productive stock portfolio.
Keep in mind that, if other researchers are to use your data and interpretations when they build their theories (i.e., your reinforcer), then they must trust you implicitly. If your data was in error or you were not correct in your inference, then their theory will fail (i.e., their nightmare). This includes consistency and care with details.

Date Last Reviewed: November 17, 2002